
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- YOLO
- Selenium
- C#
- 프로그래머스
- paramiko
- windows forms
- 핑거스타일
- Docker
- Python
- Numpy
- 채보
- ubuntu
- C
- pytorch
- label
- error
- C++
- SSH
- nvidia-smi
- Visual Studio
- mysql
- 오류
- pandas
- Linux
- VS Code
- 기타 연주
- 컨테이너
- pip
- OpenCV
- JSON
Archives
- Today
- Total
기계는 거짓말하지 않는다
Python Pandas 기본통계 본문
기본통계
import pandas as pd
data = pd.read_csv("임의데이터.csv", encoding="euc-kr", index_col="번호")
print(data)
print("=" * 30)
print(data.describe().round(3)) # 요약
print("-" * 30)
print(data[["수량", "단가"]].mean()) # 수량, 단가의 평균
print("-" * 30)
print(data[["수량", "단가"]].max()) # 수량, 단가의 최댓값
print("-" * 30)
print(data[["수량", "단가"]].min()) # 수량, 단가의 최솟값
print("-" * 30)
print(data.loc[[1, 3]].mean()) # 행 선택 후 각 컬럼 평균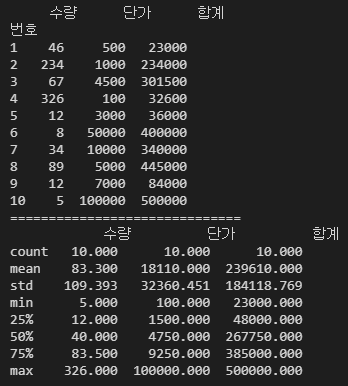

describe의 25%, 50%, 75%의 의미는 데이터의 25%, 50%, 75%가 어떤 값 이하의 값을 가지고 있다는 것을 의미한다.
예를 들어 수량의 25%는 12이하의 값을 가지고 있다.
Group By
import pandas as pd
data = pd.read_csv("임의데이터2.csv", encoding="euc-kr", index_col="번호")
print(data)
print("=" * 30)
print(data.groupby("번호").mean()) # index가 지정되지 않아도 column으로 가능
print("-" * 30)
print(data.groupby("번호").mean().head(n=3)) # 앞에서부터 데이터 3개만 출력
print("-" * 30)
print(data[["수량", "단가"]].groupby("번호").mean().head(n=3)) # column 선택


'Python' 카테고리의 다른 글
| Python OpenCV (1) 기본 이미지 다루기 (0) | 2021.07.11 |
|---|---|
| Python UnicodeDecodeError (0) | 2021.07.10 |
| Python Pandas 정렬 (0) | 2021.07.03 |
| Python Pandas 기본 연산 (0) | 2021.07.03 |
| Python Pandas(Panel Data) (0) | 2021.07.01 |
Comments

